과 TDD — AI 코딩 에이전트 시대의 새로운 흐름")



트랜스포머 아키텍처 설명
이 아키텍처는 자연어 처리 작업에서 이전 세대의 RNN들보다 성능을 크게 향상시켰으며, 재생성 능력의 폭발적인 증가를 이끌었습니다.

트랜스포머 아키텍처의 가장 큰 장점은 문장 속 모든 단어의 관련성과 맥락을 학습하는 능력입니다. 각 단어가 이웃하는 단어와의 관계뿐만 아니라 문장 속 모든 다른 단어와의 관계를 학습합니다. 이는 모델이 각 단어가 입력 문장 내 어디에 위치하든 서로 얼마나 관련이 있는지 학습할 수 있게 합니다.

이것이 바로 트랜스포머 아키텍처의 핵심 특성인 ‘셀프 어텐션’입니다. 이는 입력 문장 전체에서 단어 간의 관계를 학습하고 이해하는 능력을 개선합니다.

트랜스포머 아키텍처는 인코더와 디코더, 두 부분으로 나뉩니다. 이 두 부분은 함께 작동하며, 서로 많은 유사점을 공유합니다. 또한 모델은 텍스트를 처리하기 전에 먼저 텍스트를 토큰화해야 합니다. 이는 단어를 숫자로 변환하는 과정으로, 각 숫자는 모델이 처리할 수 있는 가능한 모든 단어의 사전에서 위치를 나타냅니다.



이제 입력이 숫자로 표현되면, 임베딩 계층으로 전달할 수 있습니다. 이 계층은 훈련 가능한 벡터 임베딩 공간이며, 각 토큰이 벡터로 표현되고 그 공간 내에서 고유한 위치를 차지합니다. 이러한 임베딩 벡터 공간은 자연어 처리에서 일정 시간 동안 사용되어 왔으며, 이전 세대의 언어 알고리즘들도 이 개념을 사용했습니다.

인코더나 디코더의 기초로 토큰 벡터를 추가하면서, 위치 인코딩도 추가합니다. 이는 단어 순서의 정보를 보존하고, 단어의 문장 내 위치의 관련성을 잃지 않게 합니다.


이후, 이 결과 벡터를 셀프 어텐션 계층으로 전달합니다. 여기서 모델은 입력 시퀀스 내 토큰 간의 관계를 분석합니다. 트랜스포머 아키텍처는 실제로 ‘멀티헤드 셀프 어텐션’을 가지고 있습니다. 이는 여러 셋의 셀프 어텐션 가중치, 또는 헤드가 독립적으로 병렬로 학습된다는 것을 의미합니다.


LLAMA model.py
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
"""
Perform a forward pass through the TransformerBlock.
Args:
x (torch.Tensor): Input tensor.
start_pos (int): Starting position for attention caching.
freqs_cis (torch.Tensor): Precomputed cosine and sine frequencies.
mask (torch.Tensor, optional): Masking tensor for attention. Defaults to None.
Returns:
torch.Tensor: Output tensor after applying attention and feedforward layers.
"""
h = x + self.attention.forward(
self.attention_norm(x), start_pos, freqs_cis, mask
)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
마지막으로, 모든 어텐션 가중치가 입력 데이터에 적용되면, 출력은 완전 연결 피드포워드 네트워크를 통해 처리됩니다. 이 계층의 출력은 각 토큰에 대한 확률 점수에 비례하는 로짓 벡터입니다. 이 로짓들은 마지막으로 소프트맥스 계층을 통과하면서, 각 단어에 대한 확률 점수로 정규화됩니다. 이러한 출력은 어휘의 모든 단어에 대한 확률을 포함하므로, 여기에는 수천 개의 점수가 있을 가능성이 높습니다.


Transformer 모델의 동작 원리
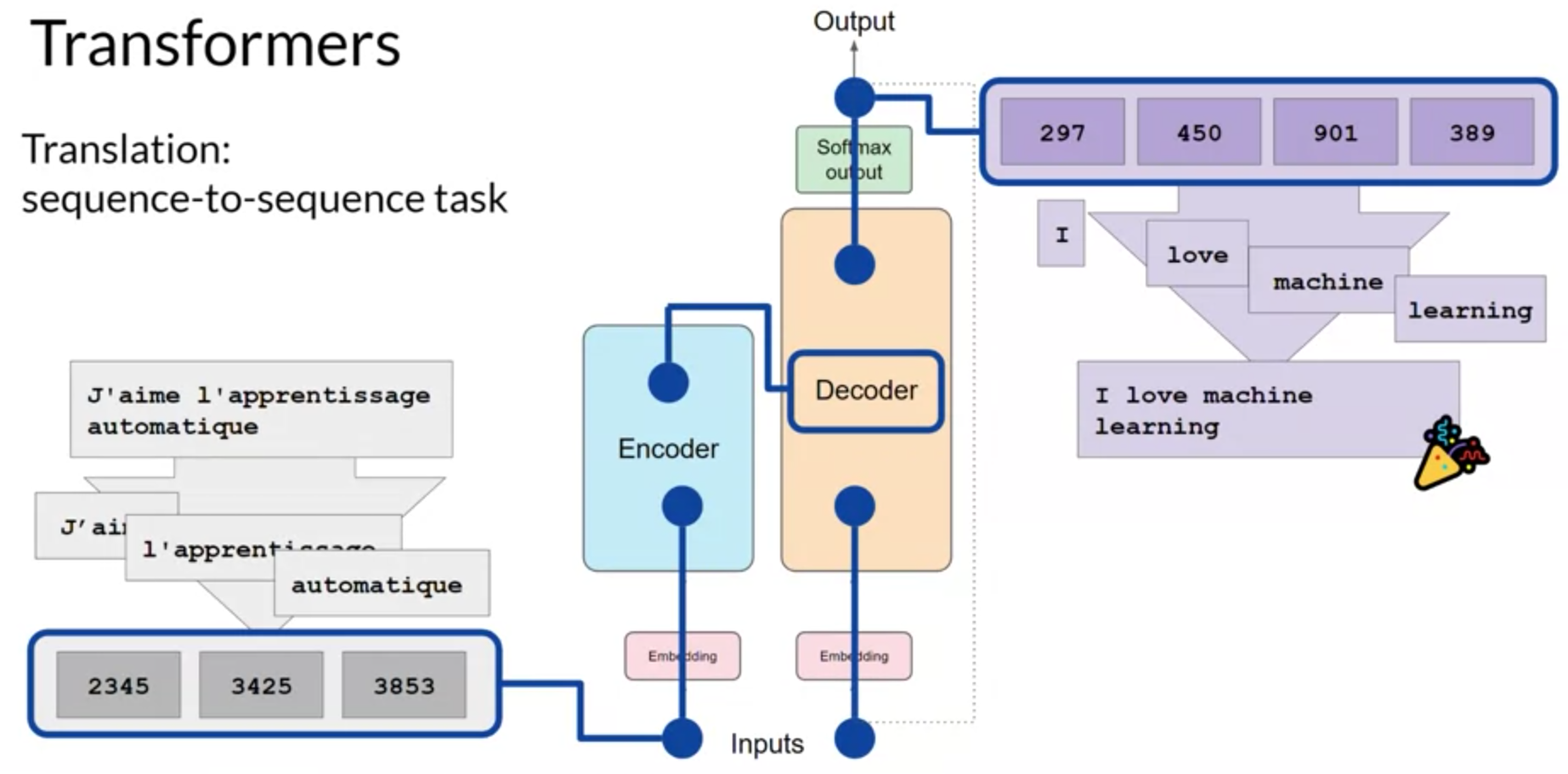
Transformer 모델은 인코더와 디코더라는 두 가지 주요 부분으로 구성되어 있습니다. 인코더는 입력 시퀀스(문장 또는 단어의 시리즈)를 깊은 표현으로 변환하며, 이는 입력의 구조와 의미를 포착합니다. 디코더는 이 인코더의 출력과 자체 입력을 사용하여 새로운 시퀀스를 생성합니다.
문장을 다른 언어로 번역하는 예제를 통해 이 과정을 설명합니다. 예를 들어, ‘Je adore l’apprentissage automatique’이라는 프랑스어 문장을 영어로 번역하는 과정을 보여줍니다. 이 입력 문장은 인코더를 통해 깊은 표현으로 변환되고, 이 표현은 디코더의 입력으로 사용됩니다. 디코더는 이를 사용하여 영어 단어를 하나씩 생성하며, 이 과정은 시퀀스 종료 토큰이 예측될 때까지 반복됩니다. 결과적으로, ‘나는 기계 학습을 사랑한다’라는 번역된 문장을 얻게 됩니다.

완전한 트랜스포머 아키텍처는 인코더와 디코더 컴포넌트로 구성되어 있습니다. 인코더는 입력 시퀀스를 입력의 구조와 의미에 대한 깊은 표현으로 인코딩합니다. 디코더는 입력 토큰 트리거를 작업으로 사용하여, 인코더의 맥락적 이해를 사용하여 새로운 토큰을 생성합니다. 이는 일부 정지 조건이 충족될 때까지 루프에서 이루어집니다.

텍스트는 또한 Transformer 모델의 다양한 변형을 설명합니다. 예를 들어, BERT는 인코더만을 사용하는 모델의 한 예이며, BART와 T5는 인코더와 디코더 모두를 사용하는 모델의 예입니다. GPT 모델 계열, BLOOM, Jurassic, LLaMA 등은 디코더만을 사용하는 모델의 예입니다.

마지막으로, 이 텍스트는 이러한 모델을 사용하여 자연어 처리 작업을 수행하는 방법에 대한 기본적인 이해를 제공하려고 합니다. 이는 ‘프롬프트 엔지니어링’이라고 불리며, 사용자의 명령을 모델이 이해하고 적절하게 반응할 수 있는 형태로 제공하는 과정입니다.
Transformers: Attention is all you need
“Attention is All You Need”는 2017년에 Google의 연구자들이 발표한 연구 논문으로, 우리가 현재 알고 있는 GPT, PaLM 등의 LLM 모델의 기반을 형성한 새로운 아키텍처인 Transformer 모델을 소개했습니다. 이 논문에서는 전통적인 순환 신경망(RNNs)과 합성곱 신경망(CNNs)을 완전히 대체하는 attention 기반 메커니즘을 제안하였습니다.
Transformer 모델은 입력 시퀀스의 표현을 계산하기 위해 self-attention을 사용하여 장기적인 의존성을 파악하고 효과적으로 계산을 병렬화할 수 있습니다. 저자들은 이 모델이 여러 기계 번역 작업에서 최첨단 성능을 보이고 RNNs 또는 CNNs에 의존하는 이전 모델을 능가함을 보여주었습니다.
Transformer 아키텍처는 각각 여러 계층으로 구성된 인코더와 디코더로 이루어져 있습니다. 각 계층은 두 개의 부분 계층으로 구성되어 있습니다: 다중 헤드 self-attention 메커니즘과 feed-forward 신경망입니다. 다중 헤드 self-attention 메커니즘을 통해 모델은 입력 시퀀스의 다양한 부분에 주목할 수 있으며, feed-forward 네트워크는 각 위치에 대해 독립적으로 완전 연결 계층을 적용합니다.
Transformer 모델은 또한 잔류 연결(residual connections)과 레이어 정규화(layer normalization)를 사용하여 훈련을 쉽게하고 과적합을 방지합니다. 또한, 저자들은 입력 시퀀스에서 각 토큰의 위치를 인코딩하는 위치 인코딩 체계를 도입하였는데, 이를 통해 순환적이거나 합성곱적인 작업 없이도 시퀀스의 순서를 파악할 수 있게 되었습니다.